Modelos de equações estruturais
Aula 1 — Revisão multivariada
Um pouco sobre mim…
Bacharel em Estatística pela Universidade de Brasília — UnB (2025)
Gerente de projetos ESTAT (2023)
Implementou o Github da ESTAT, template e outras padronizações (2023)
Idealizou, criou e liderou o squad de padronização ESTAT (2023)
Reconhecimentos: Membro inovador (2023), Membro Qualidade e excelência (2023), Membro valoroso - Ousadia (2023)
Estagiário NUADE — STF (2023-2025)
Mais informações no meu site
Contato: brunogtoledo96@gmail.com

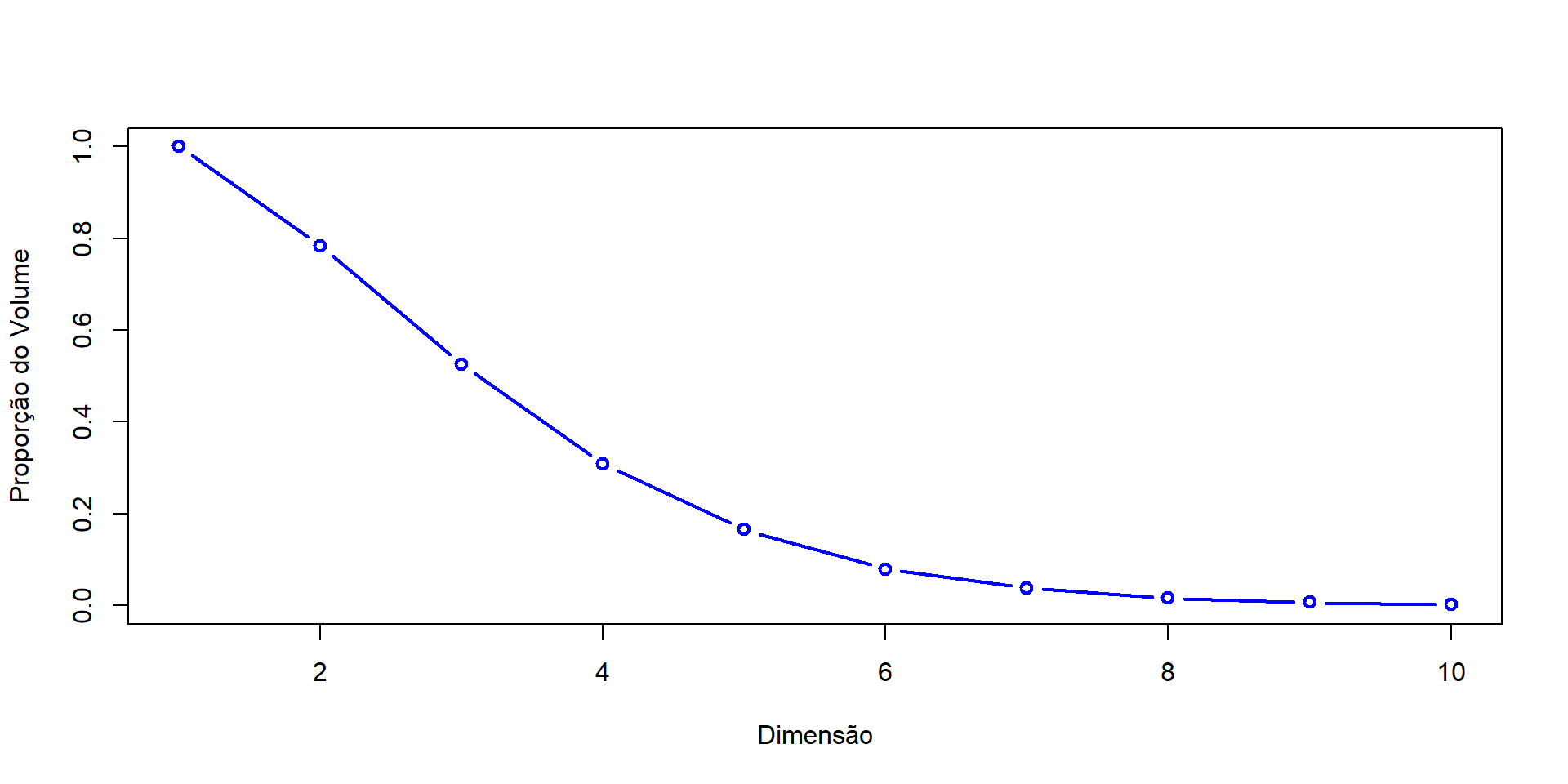
Maldição da dimensionalidade
À medida que p (número de variáveis) cresce, o espaço de dados torna-se esparso.
Consequentemente, a informação pode se perder!
Correlações espúrias aumentam → surge a necessidade de redução de dimensionalidade.
Observar critérios de quantidade de covariáveis (\(p\)), em relação ao número de observações (\(n\)).

O queijo suíço n-dimensional: Todo o volume está na casca do queijo (não há mais bolhas de ar)
Considere uma hiperesfera inscrita em um hipercubo. A medida que aumentamos a dimensionalidade de ambos, o volume da hiperesfera em relação ao hipercubo tende à zero.